Chrome AI 的愿景简单而又远大:让Chrome和Web对所有开发者和所有使用者都更加智能。所有开发者是指任何技能等级的Web开发者、Chrome扩展程序开发者。无论你是否是人工智能专家,人工智能都应该易于使用。而所有用户则意味着让所有用户都能自由使用人工智能。而不仅仅是那些使用超高端设备和购买了高级服务的用户。
2025年有一件事是肯定的,那就是AI无处不在,当AI无处不在时,它当然也会出现在Chrome中。本文将分成以下三个部分:
- 介绍Builtin AI的概念
- 浏览一遍所有的API
- 一些新的有趣的能力
介绍 Built-in AI
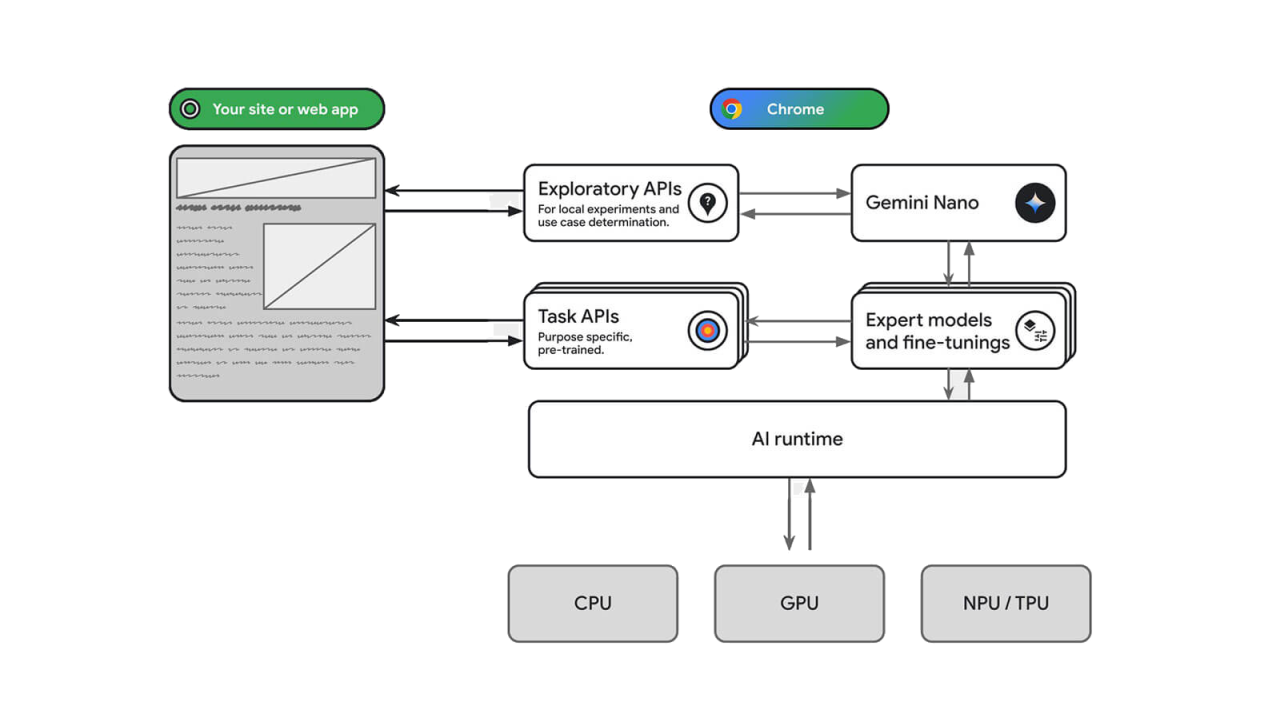
事实上,Chrome团队很早就内置了较小的专家模型在Chrome中,例如用于翻译和语言检测的模型。但也有一些不太明显的功能,例如通知提示预测,以阻止垃圾通知提示等。现在,Built-in AI的新功能是,在Chrome中新增了通用大语言模型,简称LLM。具体来说,它实际上是一个相对较小的LLM,名为Gemini Nano。与前面提到的较小的专家模型不同,Gemini Nano默认不被内置在Chrome浏览器中。一旦网页应用程序想要使用它,就会根据需要动态下载。没有被内置在Chrome中的原因是,虽然对于LLM来说,它很小,但他仍然是一个相对较大的资源。作为通用的LLM,Gemini Nano可以针对文字摘要、创意写作等特定任务进行优化,这是通过微调来实现的。结合专家模型、Gemini Nano和微调,Chrome向开发者提供了一套上层API。使浏览器能够将开发者的意图、最佳模型和针对当前任务的微调相匹配。这与使用WebGPU、WebNN来运行AI模型的底层方法是互补的。
Built-in AI的优势如下:
- 敏感数据的本地处理
- 流畅的用户体验
- 更好地利用AI
- 离线使用 AI
浏览所有API
在深入探讨细节之前,先声明一下。部分API处于有限可用状态,已发布的API需要使用Chrome 138以上的版本。
Prompting
首先是自由形式的Prompt API,针对Chrome扩展程序的版本已经在Chrome 138中发布,针对Web侧API,需要使用Chrome 128以后的版本,在flag中开启测试。Prompt API是用来测试开发者在使用 AI 时想要用来做什么的试验场。作为自由形式的 API,你可以指示 Prompt API 执行几乎任何LLM可以进行的操作。
1// Prompt API 使用示例
2const session = await LanguageModel.create();
3const response = await session.prompt(
4 "为一个五岁的孩子解释量子计算。"
5);
6
7/**
8好呀!想象一下你有一枚普通的硬币。它要么是正面,要么是反面,对吧?它只能是其中一个。
9**量子计算有点像一个神奇的硬币!**
10这个神奇的硬币可以同时是正面和反面! 🤯 难以置信,对不对? 它不是在旋转中,而是同时存在两种可能性! 我们称这种神奇的硬币为 **“量子比特” (qubit)**。
11普通的计算机使用 **“比特” (bit)** 来存储信息,比特要么是 0,要么是 1 (就像普通硬币的正面或反面)。 量子计算机用量子比特!
12因为量子比特可以同时是 0 和 1,所以它可以尝试很多不同的答案,比普通计算机快得多!
13[...]
14**简单总结:**
15* **比特 (bit):** 只能是 0 或 1,就像一个普通硬币。
16* **量子比特 (qubit):** 可以同时是 0 和 1,就像一个神奇的硬币,可以同时是正面和反面!
17* **量子计算:** 用量子比特来解决难题,比普通计算机快得多!
18**/1// Prompt API for Chrome Extension 使用示例
2const article = getArticleFromPage();
3const session = await chrome.aiOriginTrial.LanguageModel.create();
4const response = await session.prompt(
5 `为一个五岁的孩子解释这篇文章:${article}`
6);Writing
Summarizer API
1const blogPost = document.querySelector('article').textContent;
2const summarizer = await Summarizer.create({
3 type: "headline",
4 length: "short"
5});
6const headline = await summarizer.summarize(blogPost);
7// "_Find inner peace amidst the noise; true happiness lies within._"Writer API
1const writer = await Writer.create({ sharedContext });
2const blogPost = await writer.write(
3 "写一篇关于世界正在变得更好的文章"
4);
5// “世界正在改变:一些信号与进展...”Rewriter API
1const rewriter = await Rewriter.create({
2 sharedContext,
3});
4const rewrittenBlogPost = await rewriter.rewrite(blogPost, {
5 tone: "less-formal"
6})
7// "世界正在不断发展:愿景与进展..."Translating
Language Detector API
1const languageDetector = await LanguageDetector.create();
2const detectedLanguages = await languageDetector.detect(
3 "今天发生了什么有趣的事儿?"
4);
5const detectedLanguage = detectedLanguages[0]
6// {confidence: 0.9998757839202881, detectedLanguage: 'zh'}Language Detector 的 detect 函数,返回一个语言检测对象数组,每个对象都包含置信度和检测到的语言。 Language Detector API 与 Translator API 完美搭配,Translator API 允许你将源语言翻译成目标语言。
1const translator = await Translator.create({
2 sourceLanguage: detectedLanguage,
3 targetLanguage: "en"
4});
5const translation = await translator.translate(
6 "今天发生了什么有趣的事儿?"
7);
8// "What interesting things happened today?"至此,我们浏览了所有的API,你发现了吗,所有实例都是平等创建的。从LanguageModel到Translator,它们都是通过一个 create 函数以相同的方式创建,在某些情况下,这个函数会接受一些可选参数。为了简洁起见,我在某几个代码示例中跳过了这一点。
1await LanguageModel.create();
2await Summarizer.create();
3await Writer.create();
4await Rewriter.create();
5await LanguageDetector.create();
6await Translator.create();刚才提到,Gemini Nano不会包含在Chrome本身中,需要动态下载,那么,我们是怎么知道用户侧的模型是否已经准备好? 可用性函数有一个一致的方法。
1await LanguageModel.availability();
2await Summarizer.availability();
3await Writer.availability();
4await Rewriter.availability();
5await LanguageDetector.availability();
6await Translator.availability();- 如果用户侧不支持,它会响应 unavailable。
- 当用户侧支持,并且模型可以下载时,它会响应 downloadable。
- 正在下载时,它会响应 downloading。
- 当模型已准备好时,它会响应 available。
这些 API 的形态以及你刚刚看到的一致性,也源于 Chrome 团队在将这些 API 孵化项目迁移到 W3C 的 Web 机器学习社区组时收到的反馈。 所有三个 API 系列,即Prompt API、Writing API 和 Translating API,都包含在 Web 机器学习社区组的章程中。 Chrome团队正在与社区和其他浏览器供应商合作,使它们能够一致。
- https://github.com/webmachinelearning/prompt-api
- https://github.com/webmachinelearning/writing-assistance-apis
- https://github.com/webmachinelearning/translation-api
随着这些 API 的一致性工作顺利进行,在 Chrome 138 中已经发布首批 API。具体来说,是如下API:
- Prompt API for Chrome Extension
- Summarizer API
- Translator API
- Language Detector API
剩下两个 API 正在推进中,已经进入了Chrome 138版本的原始试用版:
- Writer API
- Rewriter API
新的能力
Proofreader API
已经有很多开发者,都在尝试使用自由形式的Prompt API开展校对工作,当这件事的需求量增加时,这个能力就应该被抽象,Chrome团队针对这种任务对模型进行了微调,推出了Proofreader API。 通过Prompt API收集大家的需求,从而形成更细粒度的抽象,正是Prompt API的使命。Proofreader API可以在以下问题进行校对:
- 拼写问题
- 标点问题
- 大小写问题
- 介词问题
- 漏掉某个单词
- 语法问题
1const text = 'Thsi Text have issues!';
2// This [spelling] text [copitalization] has [grammar] issues!
3const proofreader = await Proofreader.create({
4 includeCorrectionTypes: true,
5 includeCorrectionExplanations: true,
6 expectedInputLanguages: ["en"]
7})
8
9const {corrections, corrected} = await proofreader.proofread(text);
10console.log('Corrected version', corrected);
11for (const correction of corrections) {
12 console.log('Individual correction', correction);
13}Proofreader 的 proofread 函数,会返回一个包含详细更正对象的数组,以及完整的更正后的输入字符串。
1{
2 "corrected": "This text has issues!",
3 "corrections": [
4 {
5 "startIndex": 0,
6 "endIndex": 3,
7 "correction": "This",
8 "type": "spelling",
9 "explanation": "The word 'This' had two transposed letters."
10 },
11 ...
12 ]
13}每个更正都有一个相对于输入字符串的起始索引、结束索引、实际的更正,以及更正类型和说明(取决于你是否选择了)。
Proofreader API 可以在 Chrome 139 以上的版本中开启测试。 请访问 Proofreader Playground 体验 Proofreader API 的强大能力。
Multimodal API
Prompt API with image input
当 Prompt API 支持图像理解后,解锁了一些新的用例,例如让 AI 描述一张图片。如果你运营一个博客平台,你可以让模型为已上传的图片提供替代文本建议,然后用户可以进行优化和调整。另一种情况是,根据产品图片获取产品描述,例如用于电商平台。或者,你可以使用该模型从图片中提取文本信息,例如从食谱扫描中提取信息以保存手写食谱集。该 API 也继承了 Gemini 模型在OCR方面的强大能力。
1const session = await LanguageModel.create({
2 expectedInput: [{ type: "image" }]
3});
4
5const referenceImage = document.querySelector("img");
6const userDrawnImage = document.querySelector("canvas");
7
8const response = await session.prompt([
9 "Give an artistic critique of how well the second image matches the first:",
10 { type: "image", content: referenceImage },
11 { type: "image", content: userDrawnImage }
12]);
13console.log(response);该能力支持接收任何视觉对象,从图像元素到图像块,再到图像位图、视频单帧或画布对象。
请访问 Prompt API with image input Playground 体验 Prompt API with image input 的强大能力。
Prompt API with audio input
假设你有一个在线播客录制应用,你可以使用 Prompt API 创建转录建议,然后人工审核人员可以对其进行改进。如果你想添加音频片段的文本搜索,此API也非常有用。假设你有一个很长的播客,你想让用户搜索他们感兴趣的部分。另外你也可以对音频进行分类,例如,将音频文件按音乐风格分类。
1const session = await LanguageModel.create({
2 expectedInput: [{ type: "audio" }]
3});
4
5const audioBlob = await (await fetch("speech.mp3")).blob();
6
7const response = await session.prompt([
8 "Transcribe this speech:",
9 { type: "audio", content: audioBlob },
10]);
11console.log(response);请访问 Prompt API with audio input Playground 体验 Prompt API with audio input 的转录能力。
带有图像理解的 Prompt API 和支持音频输入的 Prompt API 将在 Chrome 139 中进入测试版本。
Chrome团队还提供了内置的 AI Playground ,可以让你进一步探索所有的Built-in AI API。

最后,让我们回顾一下以上讨论的内容。 首先,四个API已经在Chrome 138 中发布:用于 Chrome 扩展程序的Prompt API、Summarizer API、Language Detector API 和 Translater API。 用于 Web 的 Prompt API仍然处于测试状态。 其次,两个 API 移入 Origin Trail。即Writer API 和 Rewriter API。 第三,三个全新的 API,可在flag中开启进行测试。 它们分别是:支持图像输入的Prompt API、支持音频输入的Prompt API,以及 Proofreader API。
请查看 Built-in AI 最新进展: https://developer.chrome.com/docs/ai/built-in
希望你可以享受使用 Built-in AI的乐趣。祝你编程愉快!